
|
Intro Let us present our experience with massive offline Data Mining using several open source technologies on weekly batch of 1TB historical data for the past 10 years with +400 features. We will present the old flow and the improvements made by using Apache Spark and S3. Problem The problem we have been dealing with is a weekly batch ETL process for our back-end models training. We train classification models and use them in real-time trading for trend classification and position entry. This process is performed at the end of a trading week, but when the markets go crazy, we would rerun the training to get fresh decision making. We have been using WEKA (Waikato Environment for Knowledge Analysis) as the main source for Machine Learning algorithms and Data Mining. WEKA has everything you want: filters, classifiers, ensembles and feature selectors under the Java API. We begin with a simple Java application to filter, clean, transform and train classification models. The problem is that the application runs on single CPU and WEKA was not designed to be used in multi-threaded environments. Processing 1TB of historical data with average dataset size of 500MB each and every week leads to applications running for days, sometimes even building models before the trading week is ended. 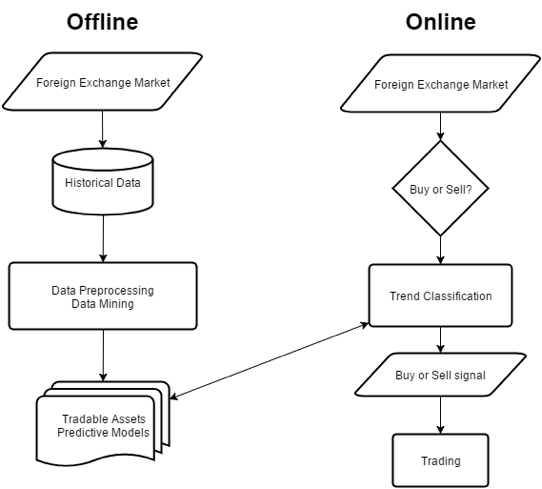 Offline batch ETL and online trading engine flows Solution We decided to incorporate Apache Spark for the job. Moreover, instead of using HDD we moved to S3 in order to avoid storage limitations. Spark is a distributed computing engine on top of classical map-reduce technology. It improves the running time by utilizing in memory computations with small computation units called tasks. Spark's key data structure is RDD (Resilient Distributed Dataset) which allows partitioning across multiple cluster nodes and separated task execution with atomic operators. Once your computations are independent, you can utilize the full power of your cluster by simultaneously processing data. Apache Spark provides fast Machine Learning functionality by additional library called MLlib. The library provides encoders, classifiers and ensembles. Nevertheless, we can get more flexibility using WEKA in our use case. 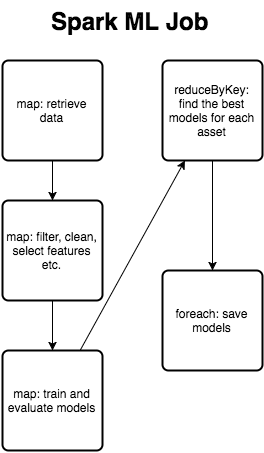 Results
We have been trading with 6 chart periods: M5, M15, M30, H1, H4 and D1. Thus we have been running batch Data Mining processes for each period. The running time of a simple Java application was ranging from 1 hour to 22 hours on standard i5 core with 12GB memory. We have been running the Spark job on 32 Xeon cores with 60GB memory and the running time was reduced to range from 10 minutes to 2 hours. This is a huge improvement. Check out the following links for more info: WEKA: http://www.cs.waikato.ac.nz/ml/weka/ Apache Spark: http://spark.apache.org/
0 Comments
 Let's make a simple and quick introduction to one of the most interesting fields today - Data Mining. There is a wide range of Data Mining applications. We should integrate Data Mining in our FX trading.
FX, FOREX or the Foreign Exchange FX is the biggest market in terms of daily traded volume. It has three main levels of participants: the big boys, the intermediate level and simple traders as you and me. It has a speculative nature, which means most of the time we do not exchange goods. We care only for the difference and wish to buy low and sell high or sell high and buy low. By short or long operations we can gain pips. Depending on your trading volume, pip value can range from one cent to 10$ and more. This is the major way to make money in the FX market (alongside with Carry Trade, Brokering, Arbitrage and more). Notice that the FX market is huge but is suitable for all levels of players. Think of the FX market as an infinite supermarket with infinite number of products and customers, but it also has an infinite number of cashiers. Meaning there is an equal amount of opportunities for all. Data Mining and Machine Learning Data Mining is a mature sub field of Computer Science. It's about a lot of data and non trivial extraction of usable knowledge from massive amounts of data. It's done by Intelligent data processing using Machine Learning algorithms. Data Mining is not just CRUD (Create, Read, Update and Delete). We have several Data Mining methods. Hereby the methods and some applications.
Algorithmic Trading Algorithmic Trading is an automated execution of a trading algorithm. In our case, the trading algorithm comes from the mining. The automated trading is done by some king of programming language. Speed and robustness are key points here: human trader cannot beat the computer program regarding those attributes. It could be HFT (High Frequency Trading) and low level programming (as C++) or long term trading and high level programming (as Java). Mix Algorithmic Trading with Data Mining Mixing Data Mining in Algorithmic Trading is important. The most important thing is data. A simple principle states that if your data is not good enough, your models will not be good enough (GIGO). It is all about creating a model, implementing it and testing it (as always). Currently this flow is mostly manual. Data Mining Software There are many open source software options in the field of Data Mining. WEKA is a Data Mining framework originated in the University of Waikato, Hamilton, New Zealand. WEKA is written in Java and has a great API. Also you have implementations for most of the well known Machine Learning algorithms. Summary Mixture of good tools is vital. There are too many possible trading models. Tossing a coin is a stupid trading system but it’s a trading system. We need Data Mining to find the gold. Good tools are easy to get so good luck with the mining. Next Station If you are looking for more info about scientific FX trading your next step is exploring Data Mining tools and historical data.  A/B testing is a well known principle in Statistics for evaluating hypotheses. We are comparing two almost identical flows with a minor change in order to detect the perfect outcome. We can also apply A/B testing in the foreign exchange market for several aspects.
Let's begin with portfolio assessment. Suppose you are given two portfolios and you are looking for an investment. So how you decide which portfolio is perfect for you? A/B testing can help. You could invest a small amount in both of them and compare, or just follow the performance and evaluate the final profit. We can also evaluate two Expert Advisers for performance finally being able to choose the best one. To asses the volatility and robustness of a trading system, we can also evaluate the same algorithm on both Demo and Real accounts in parallel. How to define a superior trading algorithm? Suppose you are given two trading algorithms A and B. You are given the black boxes without any hint on algorithm temperament. How do you evaluate the performance? Several metrics are extremely helpful. First we got profit factor: the relation of income and outcome. Second we got percentage of successful trades. Then we have ROI: return on investment. And finally Sharpe ratio: the risk of investment measurement. Although those metrics can be mirrored and evaluated simultaneously, there is another way. Once again the A/B testing can help. We can back test the algorithms with a random split of the same historical data. Also multiple time frames for the same algorithm could lead to a better conclusion. Explore and find your own interesting and unique A/B tests. Feel free to share them with us. |
 RSS Feed
RSS Feed